

EVC (extreme value correction) is a method that corrects optimistic estimates in search algorithms. We applied it to the rule induction, as one of main problems in rule induction is that the state-of-the-art rule evaluation measures do not take searching into account. This problem has been addressed by several authors (see [1] and [2]).
Perhaps the easiest to illustrate the problem will be with an experiment on artificial data set (see [3] for more ellaborate description of experiments and results).
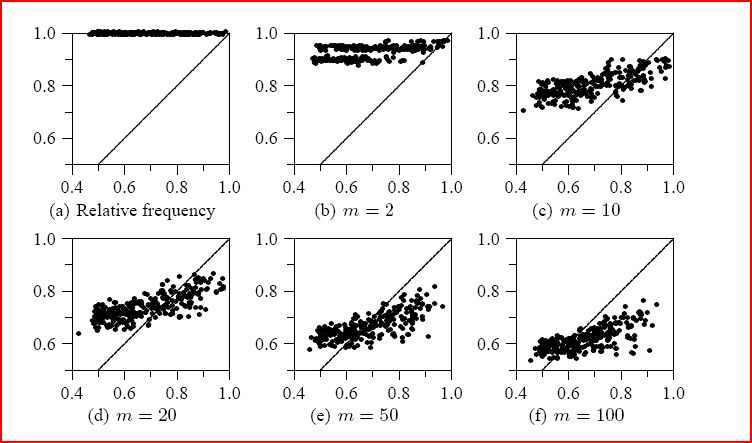
We induced several rules using m-estimate of probability as evaluation measure. As data is artificial we knew for each rule the correct probability (x axis) and estimated (y axis), therefore we would like to have dots in the above graphs put on the diagonal axis. As you can see relative frequency is completly optimistic - the algorithm will always find a 100% pure rule, although that is not true for the whole population. Using higher settings of m does improve the slope, however not completly and, eventually, all estimates will become pesimistic.
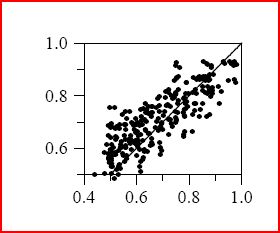
The following graph shows results of EVC corrected relative frequency on the same data set. As you can see, the result is much better than with plain m-estimate.
EVC induction of rules is implemented within Argumentation module in Orange. You can get the newevest version from Orange CVS (get Argumentation module) or here (usually a bit old). (installation: put it in Argumentation folder within Orange and run setup.py in Argumentation/Widgets directory.
See example python file EVCcn2-sample.py for an example how this module can be used.1. Best Rule
Algorithm simply finds the best evaluated rule for each class for given example, computes intersection of learning examples in these rules and uses m-estimate with m=2 for probability estimation. Prior probability is estimated by normalizing evaluations of rule (which in this case is probability, therefore it is sensible).2. Minimax
This method is an improvement of Best Rule classification, however it works only with two-class domains. Algorithm starts by identifying all rules that trigger for given example and then for each pair of opposing rules the probability is estimated the same as in Best Rule. It will happen that according to some pairs one class wins and vice-versa, therefore it is hard to decide which rule should be selected for each class. The problem can be presented as a two-opponent game with simulateous moves (von Neuman) and the result is the probability distribution of possible moves (in our case rules). Method is described in [4].3. Logit and Logit_simplify
The idea of these two classifiers is to assign a weight to each of induced rules. Classification is thus only a sum of weights that cover classifying example and the probability is computed with logit formula. The main advantage of this classifier is that the model (not only classification for one case) can be effectively visualized with a nomogram. Bellow is an example (left image) of a part of a nomogram for adult data set and on the right you can see some of best rules induced by EVC-CN2. | |
According to the nomogram, the most important rule is IF capital-gain > 6849 THEN class=">50", even though it is not the best rule according to quality (on the right image, rules are sorted according to quality). As you can see, the best rule according to quality is only at the fourth place in the nomogram, therefore the quality of rule itself does not necessary imply that the rule is the most important for classification in a nomogram.
4. Alternative learners
It is possible to set alternative learners to Logit and Logit_simplify classificators. In this case, rule classificator will only correct the alternative learner. Assume, in an imagainary data set, that tree learning works correctly only if some value of attribute X is positive. Then, if tree learner is set as alternative learner, tree will be used for instances when X is positive, but when X is negative tree will be used together with rules.[1] David D. Jensen and Paul R. Cohen. Multiple comparisons in induction algorithms. Machine Learning, 38(3):309–338, March 2000.
[2] Quinlan, J. R. and Cameron-Jones, R. M. Oversearching and layered search in empirical learning. In Proceedings of the 14th International Joint Conference on Artificial Intelligence, pages 1019--1024, Montreal, Canada, August 1995.
[3] Martin Mozina, Janez Demsar, Jure Zabkar, Ivan Bratko. Why is Rule Learning Optimistic and How to Correct It. European Conference on Machine Learning (2006). Download
[4] Martin Mozina, Jure Zabkar, Ivan Bratko. Implementation of and experiments with ABML and MLBA. ASPIC deliverable D3.4. Download