Learning Positional Features for Annotating Chess Games
Case Study: Bad Bishop
Author: Matej Guid
This website is designed to supplement the scientific papers Fighting Knowledge Acquisition Bottleneck with Argument Based Machine Learning. and Learning Positional Features for Annotating Chess Games: A Case Study with more details and explanations for interested readers. The reader may also find interesting the following PowerPoint presentation (1 MB).
Overview
1. Introduction
2. The concept of the bad bishop
3. Learning dataset
4. Explaining chess positions with arguments
5. Description of newly obtained attributes
6. Final dataset (and the arguments)
7. Final model
8. Short discussion
1. Introduction
Knowledge elicitation is known to be a difficult task and thus a major bottleneck in building a knowledge base. Machine learning has long ago been proposed as a way to alleviate this problem. It usually helps the domain expert to uncover some of the more tacit concepts. However, the learned concepts are often hard to understand and hard to extend. A common view is that a combination of a domain expert and machine learning would yield the best results. Recently, Argument Based Machine Learning (ABML) has been introduced as a combination of argumentation and machine learning. Through argumentation, ABML enables the expert to articulate his or her knowledge easily and in a very natural way. As a case study, we considered the elicitation of the well-known chess concept of the bad bishop.
The interactive procedure between the expert and ABML during knowledge elicitation was slightly improved in the paper Fighting Knowledge Acquisition Bottleneck with Argument Based Machine Learning. We will focus here on this more advanced procedure only. Through a case study, we present an application of ABML, which combines the techniques of machine learning and expert knowledge, to the construction of a more complex positional feature, the bad bishop. Such features may not always be suitable for evaluation functions of chess-playing programs, where time spent on heuristic search is important (besides, appropriate weights of these features should be determined). Nevertheless, they could serve well for the purpose of annotating chess games.
2. The concept of the bad bishop
There is a general agreement in the chess literature and among chess players about the intuition behind
the concept of bad bishop. However, the formalisation of this concept is difficult even for chess experts.
John Watson (Secrets of Modern Chess Strategy, Gambit Publications, 1999) gives the following definition as traditional: a bishop that is on the same colour of squares as its own pawns is bad, since its mobility is restricted by its own pawns and it does not defend the squares in front of these pawns. Moreover, he puts forward that centralisation of these pawns is the main factor in deciding whether the bishop is bad or not. In the middle game, he continues, the most important in this aspect are d and e pawns, followed by c and f pawns, while the rest of the pawns on the same color of a square as the bishop, are irrelevant (up to the endgame, where they might again become an important factor for determining the goodness of the bishop).

The example in the above figure is taken from the classic book by Aaron Nimzovich, The Blockade. The black bishop on c8 is bad, since its activity is significantly hindered by its own pawns. Furthermore, these pawns are blockaded by the pieces of his opponent, which makes it even harder for black to activate the bishop.
3. Learning dataset
In the experiments, the initial learning dataset (ZIP, 20 KB) consisted of 200 middlegame positions from real chess games where the black player has only one bishop. These bishops were then a subject of evaluation by chess experts (the chess expertise was provided by woman grandmaster Jana Krivec and FIDE master Matej Guid). In 78 cases, the bishops were assessed as bad. Each position had also been statically evaluated (i.e. without applying any search) by the evaluation function of the well-known open source chess program CRAFTY, and its positional feature values served as attribute values for learning.
In the paper Learning Positional Features for Annotating Chess Games: A Case Study, we explained why it is desirable for positional features for annotating chess games to be
of static nature. Assessing bishops statically is slightly counter-intuitive from the chess-player's point of view. After a careful deliberation, the following rules were chosen for determining a bad bishop
from the static point of view. The bishop is bad from the static point of view in some position, if:
1. its improvement or exchange would notably change the evaluation of the
position in favor of the player possessing it,
2. the pawn structure, especially the one of the player with this bishop, notably
limits its chances for taking an active part in the game,
3. its mobility in this position is limited or not important for the evaluation.
In this case study, we demonstrate the construction of a static positional feature, BAD BISHOP (with possible values yes or no), which was designed for
commenting on bad bishops (possibly combined with some heuristic search).
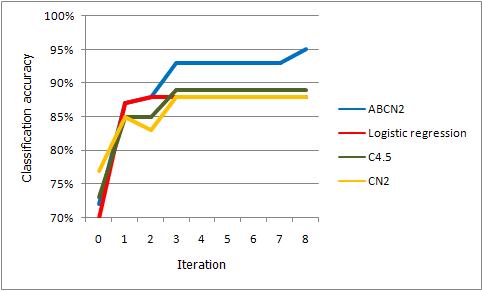
The machine learning methods' performance with CRAFTY's features only (i.e., on the initial dataset, where no other subfeatures that will be obtained by the knowledge elicitation process are included yet) is shown in the following table.
| Method |
Classification accuracy |
Brier Score |
AUC |
| Decision trees (C4.5) |
73% |
0,49 |
0,74 |
| Logistic regression |
70% |
0,43 |
0,84 |
| Rule learning (CN2) |
72% |
0,39 |
0,80 |
From the many available machine-learning methods we decided to take only
those that produce understandable models, as it will be useful later to be able
to give an explanation why a bishop is bad and not only labeling it as such.
All the accuracy and precision results were obtained through 10-fold cross
validation.
4. Explaining chess positions with arguments
In ABML, experts are asked to provide their prior knowledge in the
form of arguments for the learning examples rather than the general
domain knowledge. However, asking experts to give arguments to
the whole learning set is not likely to be feasible, because it would
require too much time and effort.
The following loop describes the skeleton of the procedure that picks out critical examples - examples
that ABML can not explain without some help:
1. Learn a hypothesis with ABML using given data.
2. Find the most critical example and present it to the expert. If a critical example can not be found, stop the procedure.
3. Expert explains the example; the explanation is encoded in arguments and attached to the learning example.
4. Return to step 1.
The main property of critical examples is that the current hypothesis can not explain them well, or, in other words, it fails to predict their class. Using
expert’s arguments, ABML will sometimes be able to explain the critical example, while sometimes this will still not be entirely possible. In such cases, we need additional information from expert.
The whole procedure for one-step knowledge acquisition is described with the next 5 steps:
Step 1: Explaining critical example.
Step 2: Adding arguments to an example.
Step 3: Discovering counter examples.
Step 4: Improving arguments.
Step 5: Return to step 3 if counter example found.
An interested reader can find more details about this procedure in the paper Fighting Knowledge Acquisition Bottleneck with Argument Based Machine Learning. In the sequel, we show some examples of how the knowledge elicitation process is performed.
Example #1: Introducing new attributes into the domain and adding arguments to an example

The rules obtained by the ABML method (ABCN2 was used) failed to classify this example as "not bad", as
was previously judged by the experts. The following question was
given to the experts: "Why is the black bishop not bad?" The experts used their domain
knowledge to produce the following answer: “The black bishop is not bad,
since its mobility is not seriously restricted by the pawns of both players.”
It turned out that the concept mentioned by the experts was not yet present in the domain attributes. A new attribute, IMPROVED BISHOP MOBILITY,
was therefore programmed and included into the domain. It is the number of squares accessible to the bishop, taking into account only own and opponents pawn structure. Based on the experts’ explanation,
the argument "IMPROVED BISHOP MOBILITY is high" was added to this example.
Example #2: Explaining counter examples and improving arguments with newly obtained attributes
Taking only the bishop’s mobility into account turned out not to be enough for ABCN2 to determine the goodness of the bishop. Also, the method, which at the time only had CRAFTY’s attributes and the
newly included attribute at its disposal, failed to find additional restrictions to improve the experts’ argument. The ABML method then presented the experts with the following counter example. This
example was classified as "bad", although the value of the attribute IMPROVED_BISHOP_MOBILITY is high.

The experts were now asked to compare the black bishops in the two examples: "Why is the black bishop bad, comparing to the previous one?" Their explanation was: "The important difference between the two
examples is the following. In this example there are more pawns on the same colour of squares as the black bishop, and some of these pawns occupy the central squares, which further restricts the bishop’s possibilities for taking an active part in the game."
Based on this description, another attribute, BAD PAWNS, was included into the domain. This attribute evaluates pawns that are on the colour of the square of the bishop ("bad" pawns in this sense). The argument given to the previous example was then extended to "IMPROVED BISHOP MOBILITY is high AND BAD PAWNS is low," and with this argument the method could not find any counter examples anymore.
Example #3: Improving arguments with existing attributes
The ABML-based knowledge elicitation process can be used to induce rules to determine both good (i.e. not bad) and bad bishops. In the following case, the experts asked to describe why the black bishop is bad. Based on their answer, another attribute was introduced into the domain: BLACK_PAWN_BLOCKS_BISHOP_DIAGONAL, which takes into account own pawns that block the bishops diagonals. The argument "BLACK_PAWN_BLOCKS_BISHOP_DIAGONAL is high" was added to the example.

However, a counter example was found by the method and was shown to the experts. The question was: "Why is this bishop in the following example not bad, while the bishop
in the previous one is bad?" The experts: "The black bishop is not bad, since together with the black queen it represents potentially dangerous attacking force that might create
serious threats against the opponent’s king."

In this case, the experts were unable to express the crucial differences between the selected examples regarding the goodness of the bishop in a way that would enable to translate her description into domain
description language. When the expert is unable to provide an argument that could be translated into domain description language, the ABML method searches for another counter example. The following example was shown to the experts.

"Why is the bishop not bad, comparing to the bishop in the previous example?" (i.e., the first example of the current subsection) The experts described the difference: "The black bishop is not bad, since its mobility is not seriously restricted, taking the pawn structure into account." Based on the experts’ commentary, the existing attribute IMPROVED BISHOP MOBILITY was used to improve the argument to "BLACK PAWN BLOCKS BISHOP DIAGONAL is high AND IMPROVED BISHOP MOBILITY is low".
5. Description of newly obtained attributes
During the process, five new attributes were included into the domain.
| Attribute |
Description |
| BAD_PAWNS |
pawns on the color of the square of the bishop - weighted according to their squares (bad pawns) |
| BAD_PAWNS_AHEAD |
bad pawns ahead of the bishop |
| BLOCKED_DIAGONAL |
bad pawns that block the bishop's (front) diagonals |
| BLOCKED_BAD_PAWNS |
bad pawns, blocked by opponent's pawns or pieces |
| IMPROVED_BISHOP_MOBILITY |
number of squares accessible to the bishop, taking into account only pawns of both opponents |
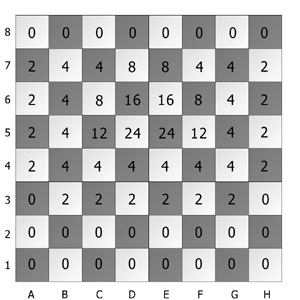
The experts designed a look-up table (left) with predefined values for the pawns that are on the color of the square of the bishop in order to assign weights to such pawns. According to Watson's definition, centralisation of the pawns has been taken into account. Several other attributes used this look-up table to assess heuristically an influence of such bad pawns on the evaluation of the bishop. Note that the table is designed for determining the goodness of the pawns that are on the color of the square of the bishop of black player. The reversed look-up table would be appropriate for determining bad bishops of white player.
To give an example of how the values of the new attributes are obtained, we will calculate the value of the attribute BAD_PAWNS_AHEAD for the position on the right. This attribute provides an assessment of pawns on the same color of square as the bishop of which they are in front of. There are three such pawns in that position: e6, d5, and a6. For each of these pawns their corresponding values are obtained from the look-up table, that is, 16, 24, and 2, respectively. The sum of these values (16 + 24 + 2 = 42) represents the value of the attribute BAD_PAWNS_AHEAD.
6. Final dataset
The ABML-based knowledge elicitation process presented in our case study consisted of eight iterations. During the process, seven arguments were attached to automatically selected critical examples, and five new attributes were included into the domain. The final dataset (ZIP, 20 KB) includes the calculated values for each newly added attribute.
7. Final model
The machine learning methods' performance on the final dataset (with new attributes included) is shown in the following table.
| Method |
Classification accuracy |
Brier Score |
AUC |
| Decision trees (C4.5) |
89% |
0,21 |
0,86 |
| Logistic regression |
88% |
0,19 |
0,96 |
| Rule learning (CN2) |
88% |
0,19 |
0,94 |
| ABCN2 |
95% |
0,11 |
0,97 |
The accuracies of all methods improved during the process, however ABCN2 (which also used the arguments given by the experts) outperformed all the others. The obtained results suggest that the performance of other algorithms could also be improved by adding appropriate new attributes. However, using arguments is likely to lead to even more accurate models.
Rules for determining bad bishops:
IF IMPROVED_BISHOP_MOBILITY < 3 AND BLACK_PAWN_BLOCKS_BISHOP_DIAGONAL >= 8 AND BAD_PAWNS_AHEAD > 16 THEN BISHOP=bad [29, 0]
IF BLACK_PAWN_BLOCKS_BISHOP_DIAGONAL >= 8 AND BAD_PAWNS_AHEAD >= 29 THEN BISHOP=bad [24, 0]
IF BLACK_PAWN_BLOCKS_BISHOP_DIAGONAL >= 20 AND IMPROVED_BISHOP_MOBILITY <= 3 THEN BISHOP=bad [18, 0]
IF BLACK_PAWN_BLOCKS_BISHOP_DIAGONAL > 4 AND BAD_PAWNS > 34 THEN BISHOP=bad [22, 0]
Rules for determining bishops that are not bad:
IF IMPROVED_BISHOP_MOBILITY >= 4 AND BAD_PAWNS <= 32 THEN BISHOP=not bad [0, 39]
IF BAD_PAWNS_AHEAD <= 1 AND BLACK_PAWN_BLOCKS_BISHOP_DIAGONAL <= 2 THEN BISHOP=not bad [0, 41]
IF IMPROVED_BISHOP_MOBILITY >= 5 AND BAD_PAWNS_AHEAD <= 28 THEN BISHOP=not bad [1, 30]
IF BLOCKED_BAD_PAWNS <= 3 AND BAD_PAWNS <= 26 AND IMPROVED_BISHOP_MOBILITY > 1 THEN BISHOP=not bad [0, 18]
IF BLACK_PAWN_BLOCKS_BISHOP_DIAGONAL <= 4 THEN BISHOP=not bad [1, 49]
8. Short discussion
The main advantage of ABML over classical machine learning is the ability to take advantage of expert’s prior knowledge in the induction procedure. This leads to hypotheses comprehensible to experts, as it explains learning examples using the same arguments as the expert did.
In our case study this was confirmed by chess experts. According to them, the final set of rules are more alike to their understanding of the bad bishop concept than the initial rules were. Furthermore, the final rules were also recognised to be in accordance with the traditional definition of a bad bishop.
Our domain experts clearly preferred the ABML approach to manual knowledge acquisition. The formalisation of the concept of bad bishop turned out to be beyond the practical ability of our chess experts (a master and a woman grandmaster). They described the process as time consuming and hard, mainly because it is difficult to consider all relevant elements. ABML facilitates knowledge acquisition by fighting these problems directly. Experts do not need to consider all possibly relevant elements, but only elements relevant for a specific case, which is much easier. Moreover, by selecting only critical examples, the time of experts involvement is decreased, making
the whole process much less time consuming.